Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Note: since this page contains many videos, please wait patiently for page loading.
TL;DR: we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference, delivering more lifelike and high-quality results across various scenarios.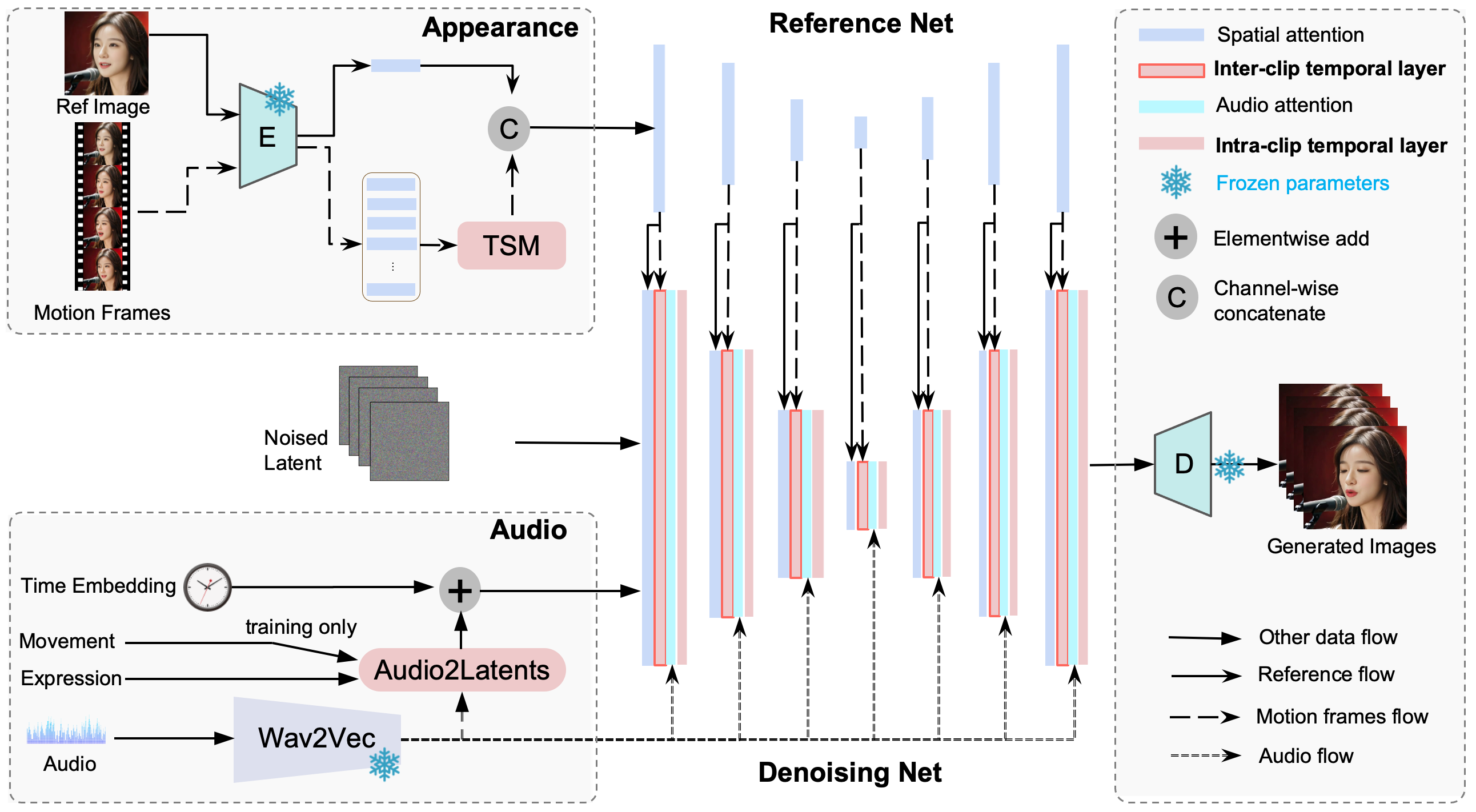
Generated Videos
Loopy supports various visual and audio styles. It can generate vivid motion details from audio alone, such as non-speech movements like sighing, emotion-driven eyebrow and eye movements, and natural head movements.
* Note that all results in this page use the first frame as reference image and conditioned on audio only without need of spatial conditions as templates.
Motion Diversity
Loopy can generate motion-adapted synthesis results for the same reference image based on different audio inputs, whether they are rapid, soothing, or realistic singing performances.
Singing
Additional results demonstrating singing
More Video Results
Additional results about non-human realistic images
Loopy also supports input images with side profiles effectively
More results about realistic portrait inputs
Comparison with Recent Methods
Additional Visual Results and Resources
Here we list the test set splits, specific times, and cropping areas for Loopy in the packaged file (link) to facilitate comparisons with Loopy.
Ethics Concerns
The purpose of this work is only for research. The images and audios used in these demos are from public sources.